YouTube video in German with automatic speech recognition captions translated into English https://youtu.be/2c9qaNqSOS0
Around this time last year (November 2021) we discussed the challenges that are linked to the evaluation of captions generated by the use of Automatic Speech Recognition (ASR) in two blogs ‘Collaboration and Captioning’ and ‘Transcripts from Captions?’
We mentioned other methods in comparison to word error rates where any mistakes in the caption are caught and provided as a percentage. This does not take into account how much is actually understandable or whether the output would make sense if it was translated or even used in a transcript.
“Word Error Rate (WER) is a common metric for measuring speech-to-text accuracy of automatic speech recognition (ASR) systems. Microsoft claims to have a word error rate of 5.1%. Google boasts a WER of 4.9%. For comparison, human transcriptionists average a word error rate of 4%. “
Helena Chen in her blog goes on to explain how to calculate WER
“Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
Where errors are:
Substitution: when a word is replaced (for example, “shipping” is transcribed as “sipping”)
Insertion: when a word is added that wasn’t said (for example, “hostess” is transcribed as “host is”)
Deletion: when a word is omitted from the transcript (for example, “get it done” is transcribed as “get done”)”
She describes how acoustics and background noises affect the results, although we may be able to cope with a certain amount of distraction and understand what is being said. She highlights issues with homophones and accents that may fail with ASR, as well as cross talk where ASR can omit one speaker’s comments, that could affect the results. Finally, there is the complexity of the content and as we know with STEM subjects and medicine this may mean specialist glossaries are needed.
Improvements have been made by the use of natural language understanding with the use of Artificial Intelligence (AI). However, it seems that as well as the acoustic checks, we need to delve into the criteria needed for improved comprehension and this may be to do with the consistency of errors that can be omitted in some situations. For an example a transcript of a science lecture may not need all the lecturer’s ‘ums’ and ‘aahs’, unless there is the need to add an emotional feel to the output. These would be counted as word errors, but actually do not necessarily help understanding.
There may also be the need to flag up the amount of effort needed to understand the captions. This involves the need to check output for automatic translations, as well as general language support.
Faith recently had COVID-19 and this really affected her arthritis. She felt so tired and upset at times. She was very upset that all her work was being affected by feeling as if she had brain fog, as well as having depleted levels of concentration. On top of all the COVID challenges, she developed repetitive strain injuries (RSI) trying to cope with her studies as well as life in general. Despite the fact that Faith’s family were now away from home much of the time, she was struggling but determined to finish her third-year project that involved access to virtual worlds with the development of three-dimensional (3D) Internet environments. This was exciting, interesting but a challenge with a write up, as well as all the coding.
Having been an administrator, she had been bored with the endless spreadsheets and databases and decided to return to her love of mathematics and design rather, than looking at poorly developed user interfaces. She wanted to be more creative and create ideas around virtual worlds that involved outdoor environments and in particular intricate garden designs, as this had become more than just a hobby. However, as her arthritis progressed and now her RSI was really affecting her dexterity, she was concerned that she would not be able to cope with so much mouse work, such as click and hold to grab a screen or multiple clicks to drag and drop items.
Taking breaks had become essential and accessing controls via keyboard shortcuts seemed to help, but the latter was not always possible when creating demonstration applications. Faith found she needed to use her left hand more and keep her right forearm in the handshake position to prevent the RSI pain. Using an upright mouse with a roller ball on the side or a pen stylus solved some issues. She really liked to be able to step through her worlds using single keys to move around and had her Mac set up with several personalised keyboard shortcuts using Control accessibility options with her keyboard. Speech recognition was good for much of Faith’s writing, when she used the dictation settings and Voice Control for the main navigation challenges on the computer. However, remembering all the commands was hard, so Faith resorted to a crib sheet!
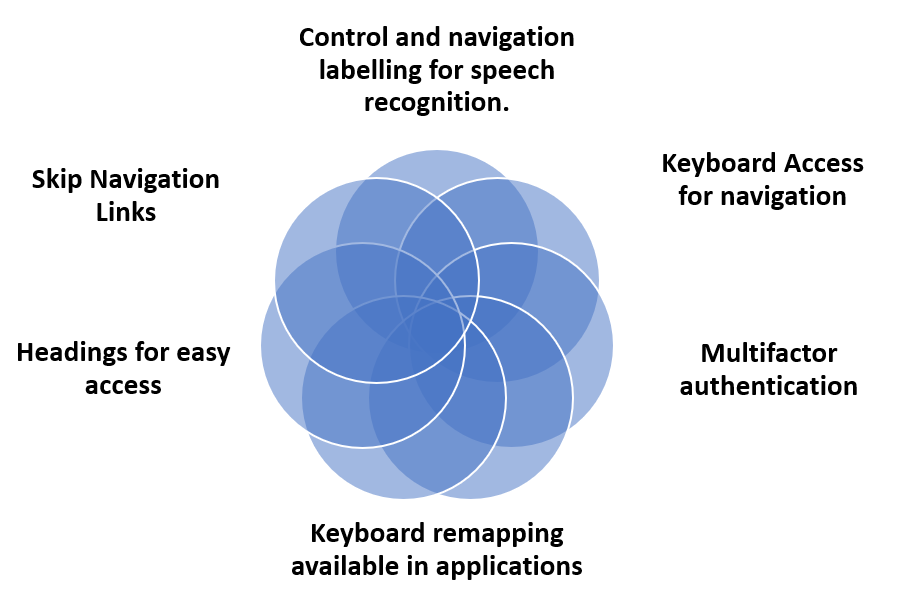
Main Strategies to overcome Barriers to Access
Strategies to overcome Barriers to Access
Multifactor Authentication. Faith finds fiddling with two devices really difficult especially when she is then required to copy a code or manage a series of numbers. She much prefers to use biometric forms of verification, such as speech, face or finger recognition; her computer and phone have her preferred finger recognition. At the moment she cannot remember passwords or phrases let alone three random words. Faith has to cope with the Microsoft authenticator app to access university sites and has a password manager system for online access. (Web Content Accessibility Guidelines (WCAG) 2.2 Success Criterion 3.3.7 Accessible Authentication)
Keyboard Access “Speech recognition can be used for dictating text in a form field, as well as navigating to and activating links, buttons, and other controls.” (W3C WAI speech recognition accessibility) The link to making this possible is to ensure that all these controls are keyboard accessible and then the mapping of the commands will work with voice controls. Example of how other criteria linked to WCAG compliance help solve the challenges faced by Faith
Keyboard remapping available in applications in order to personalise keyboard controls and make it easier to access app components. The WebAim team provide a very useful table that covers the standard keystrokes that Faith uses for the browser interactions, with hints that enhance accessibility.
Control and navigation labelling for speech recognition. The way controls are labelled can make all the difference when accessing sites using a keyboard or speech. Faith finds she has to use her spoken command crib sheet more and more to access controls and to navigate around pages if she cannot use her mouse and these commands depend on the labels that have been used by the developer.
Headings for easy access. This is not just about using consistent Heading order but being clear about titles and their meaning to help Faith quickly scan down content especially if there are important instructions. This can help her concentration as well as make it easier to navigate.
Key points from Faith
“The worse thing is that I have to take regular breaks now because my concentration goes and I know if I spend more than half an hour continuously using my mouse I will be in pain for the rest of the day. I really want technology applications that are used for designing and developing apps to be more accessible as well as the apps themselves”
AbleGamers have produced a really helpful guide for developers about making ‘Accessible Player Experiences (APX)‘ that can be applied for any app development.
The subject of automatic captioning continues to be debated but Gerald Ford Williams has produced a really helpful “guide to the visual language of closed captions and subtitles” on UX Collective as a “user-centric guide to the editorial conventions of an accessible caption or subtitle experience.” It has a series of tips with examples and several very useful links at the bottom of the page for those adding captions to videos. There is also a standard for the presentation of different types of captions across multimedia ISO/IEC 20071-23:2018(en).
However, in this article transcripts are something that also need further discussion, as they are often used as notes gathered from a presentation, as a result of lecture capture or an online conference with automatic captioning. They may be copied from the side of the presentation, downloaded after the event or presented to the user as a file in PDF/HTML or text format depending on the system used. Some automated outputs provide notification of speaker changes and timings, but there are no hints as to content accuracy prior to download.
The problem is that there also seem to be many different ways to measure the accuracy of automated captioning processes which in many cases become transcriptions. 3PlayMedia suggest that there is a standard, saying “The industry standard for closed caption accuracy is 99% accuracy rate. Accuracy measures punctuation, spelling, and grammar. A 99% accuracy rate means that there is a 1% chance of error or a leniency of 15 errors total per 1,500 words” when discussing caption quality.
The author of the 3PlayMedia article goes on to illustrate many other aspects of ‘quality’ that need to be addressed, but the lack of detailed standards for the range of quality checks means that comparisons between the various offerings are hard to achieve. Users are often left with several other types of errors besides punctuation, spelling and grammar. The Nlive project team have been looking into these challenges when considering transcriptions rather than captions and have begun to collect a set of additional issues likely to affect understanding. So far, the list includes:
Number of extra words added that were not spoken
Number of words changed affecting meaning – more than just grammar.
Number of words omitted
Contractions … e.g. he is – he’s, do not … don’t and I’d could have three different meanings I had, I would, or I should!
The question is whether these checks could be included automatically to support collaborative manual checks when correcting transcriptions?
Below is a sample of the text we are working on as a result of an interview to demonstrate the differences between three commonly used automatically generated captioning systems for videos.
Sample 1
Sample 2
Sample 3
So stuck. In my own research, and my own teaching. I’ve been looking at how we can do the poetry’s more effectively is one of the things so that’s more for structuring the trees, not so much technology, although technology is possible
so starting after my own research uh my own teaching i’ve been looking at how we can do laboratories more effectively is one of the things so that’s more for structuring laboratories not so much technology although technology is part of the laboratory
so stop. In my own research on my own teaching, I’ve been looking at how we can do the ball trees more effectively. Is one thing, so that’s more for structuring the voluntary is not so much technology, although technology is part little bar tree
Having looked at the sentences presented in transcript form, Professor Mike Wald pointed out that Rev.com (who provide automated and human transcription services) state that we should not “try to make captions verbatim, word-for-word versions of the video audio. Video transcriptions should be exact replications, but not captions.” The author of the article “YouTube Automatic Captions vs. Video Captioning Services” highlights several issues with automatic closed captioning and reasons humans offer better outcomes. Just in case you want to learn more about the difference between a transcript and closed cations 3PlayMedia wrote about the topic in August 2021 “Transcription vs. Captioning – What’s the Difference?”.
Otter creates voice notes that combine audio, transcription and speaker identification for free on a desktop/laptop computer when online and with mobile and tablet apps.
Otter is a real time speech recognition service, that can recognise different speakers in recorded sessions, allow you to download the output in text and audio as well as SRT. It is really quite accurate even when using a desktop microphone with clear English speakers in a small room. We have found it useful for note taking and transcribing interviews but have not tested it in a lecture theatre. The free online version of Otter offers 600 minutes of transcription per month with unlimited cloud storage and synchronisation across devices. Visit the App Store or Google Play for more features and reviews.
The Premium version provides more features, such as names of speakers when they register and are recognised by recording a little bit of speech and 6,000 minutes of transcription per month. PC Mag provided a review in June 2018 and mentioned that with the free plan, users get 600 minutes of transcriptions per month.
ECS Accessibility Team, University of Southampton.
“I have been using the Swype Keyboard that comes with Dragon speech or voice recognition for long time on an HTC mobile running Android OS and despite the lack of a personalised voice profile, my accent, and even when used in very noisy locations like public transport or cafes, I have been very impressed by the accuracy.
Dragon remote microphone is an app that allows you to use a mobile device as a remote microphone for the full version of Dragon installed on a PC or Mac, but only if the computer and the mobile device are connected on the same Wi-Fi network.
Alternatively the Goggle Keyboard (free) comes with its own speech-to-text, although in my experience it was less accurate when compared to Swype.
Speech-to-text on a portable device like an iOS iPhone/iPad or Android phone or tablet, is quite different than having Dragon NaturallySpeaking or DragonDictate installed on a PC or Mac. The speech or voice recognition process on a portable device requires an Internet connection, since the conversion/processing is made on a remote server, and not on the device itself. So literally, your recorded voice will be sent to the US, get processed in the Nuance server and then sent back to your screen. There is no specific customisable voice profile on a portable device, that can be used in order to improve your accuracy, nor can specific words be added to the Vocabulary. For example every time I say ‘Enrico’, Dragon on my mobile transcribes “eriko” and there is no way for me to make a correction. Also Dragon installed on a proper computer, can learn to recognise very heavy accents, the same is not true for the cloud-based services.
Look out for Dragon Anywhere an app for Android and soon iOS.
One of the easiest ways of checking for the spelling of a single word when on the move and not requiring a whole document to be spell checked is to say the word into a smart phone or tablet. As long as you have one of the fairly recent versions of Android, iOS iPhone or iPad or Windows, they all have built in speech recognition. I am showing an example of how it works on an iPhone with Siri and this iOS5 hot tip has been on the web since 2012. There is an Android tutorial on using Speech to Text and one for Windows Surface speech recognition
I said to Siri – “spell /filosofical/” (spelt as said) – It not only repeated the word back to me with text to speech, but also gave me the correct spelling and dictionary definition. If I just said the word it gave me the text to speech version back and a collection of links such as the word in Wikipedia.
This comes thanks to Annie – dyslexic researcher, University of Southampton.