In the previous blog we discussed some of the metrics that we felt needed to rbe explored in order to carry out a fuller evaluation of ASR recordings in order to try to address some of the issues occurring in the output to captions and transcriptions.
Recently we have developed a range of practical metrics evaluated by a series of scores and value-added comments. This was felt necessary to solve the issue of selection bias in ASR that seems to highlight errors due to pronunciation differences affected by age, gender, disability, accents and English as a foreign language when listening to lecturers across a range of subjects. It is hoped these can be addressed by providers using differently biased input data that is customized, instead of using one single accuracy percentage to denote the performance of the ASR services. Evaluators also need to be aware of these issues and suggest the need for more inclusive training data to enable corrections to automatically occur in a proactive manner.
In the table below the list of items that may be used in a review has been expanded well beyond those usually used to find the type of word errors, omissions or additions that are occurring.
SpeakerSpeech
EnvironmentNoise
Content – What is expressed
Technology Hardware
Recording
Pronunciation Clarity Speed Loudness Pitch Intonation Inflection Accent, Age, Gender, Use of Technology Too far away / near the microphone
Ambient noise/continuous Reverberation Sudden noise Online/Offline User device Room system Conversation vs Presentation Single speaker Overlapping speakers Multi-speakers
Complexity Unusual names, locations, and other proper nouns Technical or industry-specific terms Out of Vocabulary / not in the dictionary Homonyms
Smart phone Tablet Laptop Desktop Microphone Array Headset Built-in Hand held Camera Specialist /Smart Computer Mobile
Direct audio recording Synthetic speech recording Noise-network distorted speech Connectivity Live / Real-Time Recorded
Table 1. Additional practical metrics to support the evaluation of ASR outcomes
When it comes to pronunciation or typical morphosyntactic differences in the way a language is used, developers may be able to pre-empt and automate corrections for consistent errors. An example includes articulation errors that are typical for those speaking English as a foreign language such as the omission of “th”, “v” and “rl” sounds that do not appear in some Chinese dialects.
Age and gender biases could also be improved using semi-automated annotation systems, but speaker style remains an issue that is hard to change when there is direct ‘human-machine interaction’ rather than someone reading text.
Moreover, there still remains the manual process of checking for metrics, such as those that examine the way technology is used. This type of problem can be judged visually if the camera catches the interactions and in an auditory manner, such as walking away from the microphone or turning ones back to the camera etc. AI Video content analysis is moving apace and these techniques could help us in time!
Ultimately the training data is the main issue but automated bias mitigation techniques are being explored by researchers and the outcomes look promising and there also needs to be some swift designing of a more sophisticated and adaptable ASR performance metric evaluator to automate the process of reviewing output!
This is just the start of a user needs analysis related to the way we think about Automatic Speech Recognition (ASR) challenges and our requirements for captions and transcripts to help those watching and listening to streaming videos and audio.
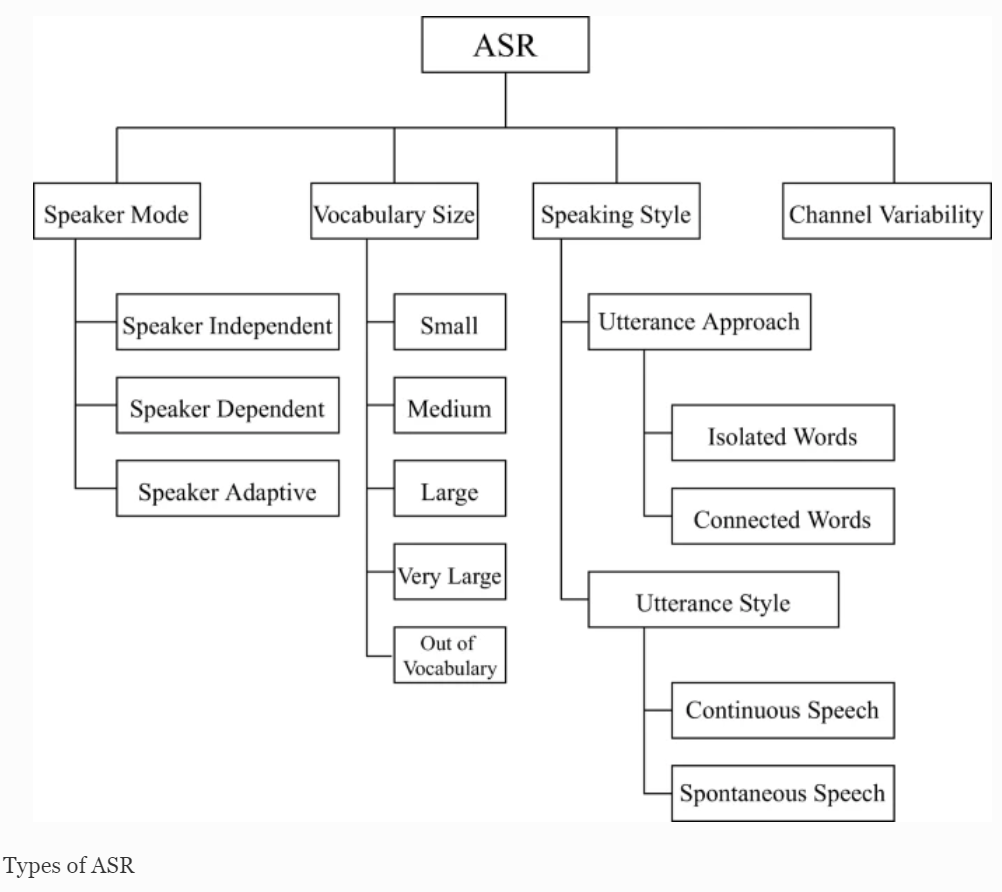
Working from left to right in the above diagram the authors of this paper ask us to think about a ‘Speaker Mode’ such as a trained speech pattern from a sole user who, with a good speaking style, can result in good ASR results. This mode is compared to an untrained speech pattern from one person or multiple speakers with overlapping conversations which can be harder for ASR models. Moving across to the ‘Vocabulary Size’ used in the conversations or presentations, there may be large and complex sections of text which, when considered alongside different ‘Speaking Styles’, can also affect output. ‘Channel Variability’, such as a noisy environment is a further challenge. The technologies used (microphones and cameras) may also be unsuitable for the best results. Finally, latency when live streaming ASR involves the time it takes for data to get to the ASR servers and back again. This process also includes how long the transcribing takes. Both types of latency has an impact on the accuracy of captions and transcriptions.
file format acronyms and others
However, having accepted all these challenges and several other issues that may have been missed, there is the essential task of thinking about user needs. In our case this involves student needs and the desire for increased flexibility in the way learning occurs at a higher education level. There remains the wish to have 100% accurate captions that fit the timeline of a conversation or presentation / lecture, but some users may wish to have different size fonts or colours as the text crosses the screen, others may wish to have key words highlighted. Then there are the transcripts that can offer easier reading by omitting many of the natural non-word insertions such as ‘ums’ and ‘uhs’, but need to accurately capture multiple acronyms to help understanding, so they can be defined at a later date.
As we explore the way applications present captions and transcripts, it is not surprising that there seem to very few discussions about personalisation and customisation of captions and transcripts for educational use. Most students are provided with instructions for the various systems, with little choice as to whether they wish to have slides on show or hidden, titles in larger text and paragraphs with timings. Then it may be important for all the inserted non-words to be left in place because they can add to the emotional content of a presentation. Some captions are offered as a stream of text as a type of transcript. This is how they are provided by YouTube, including all the timings down to two seconds apart, with phrases in long columns. The content can be copied and pasted into a document, but it is not that easy to read for note taking, with very minimal punctuation and liberal capturing of non-word insertions.
Other systems such as Otter.ai offer a downloadable transcript that has speaker recognition and key points as an outline targeted for use in meetings. These options could be handy for lecture notes. The system strips out any non-word insertions, adds punctuation and copes well with many complex words and different speakers, giving each one a number.
As a way of personalising video viewing and lecture capture, it is possible to combine the YouTube experience with captions by then converting the MP4 video file (if it is downloadable) into an MP3 format (free VLC offers this option) or use a web service and then upload it to Otter.ai as a free trial! It really does not take long and the process allows me to analyse Word Error Rates for testing accuracy, by comparing documents as well as using highlighting and adding annotations!
Warning: Obviously because the process described involves AI and automation, not every aspect of the captions or transcript output can be guaranteed to be 100% correct, so there is still the need to have manual checks in place if a verbatim output is required.
YouTube video in German with automatic speech recognition captions translated into English https://youtu.be/2c9qaNqSOS0
Around this time last year (November 2021) we discussed the challenges that are linked to the evaluation of captions generated by the use of Automatic Speech Recognition (ASR) in two blogs ‘Collaboration and Captioning’ and ‘Transcripts from Captions?’
We mentioned other methods in comparison to word error rates where any mistakes in the caption are caught and provided as a percentage. This does not take into account how much is actually understandable or whether the output would make sense if it was translated or even used in a transcript.
“Word Error Rate (WER) is a common metric for measuring speech-to-text accuracy of automatic speech recognition (ASR) systems. Microsoft claims to have a word error rate of 5.1%. Google boasts a WER of 4.9%. For comparison, human transcriptionists average a word error rate of 4%. “
Helena Chen in her blog goes on to explain how to calculate WER
“Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
Where errors are:
Substitution: when a word is replaced (for example, “shipping” is transcribed as “sipping”)
Insertion: when a word is added that wasn’t said (for example, “hostess” is transcribed as “host is”)
Deletion: when a word is omitted from the transcript (for example, “get it done” is transcribed as “get done”)”
She describes how acoustics and background noises affect the results, although we may be able to cope with a certain amount of distraction and understand what is being said. She highlights issues with homophones and accents that may fail with ASR, as well as cross talk where ASR can omit one speaker’s comments, that could affect the results. Finally, there is the complexity of the content and as we know with STEM subjects and medicine this may mean specialist glossaries are needed.
Improvements have been made by the use of natural language understanding with the use of Artificial Intelligence (AI). However, it seems that as well as the acoustic checks, we need to delve into the criteria needed for improved comprehension and this may be to do with the consistency of errors that can be omitted in some situations. For an example a transcript of a science lecture may not need all the lecturer’s ‘ums’ and ‘aahs’, unless there is the need to add an emotional feel to the output. These would be counted as word errors, but actually do not necessarily help understanding.
There may also be the need to flag up the amount of effort needed to understand the captions. This involves the need to check output for automatic translations, as well as general language support.
Hobbies: Yoga, running, actively taking part in lobbying for inclusion
Background:
Amber loves her yoga and running, excelling at school where she enjoyed an inclusive educational setting despite her severe bilateral hearing loss. She is a hearing aid user and depends on lip reading (speech reading) and Sign Language, but speaks relatively clearly. In fact, her communication skills are remarkable, thanks to the early and continuous support she received from her parents, both mathematics professors. Nevertheless, being at university was quite a challenge in the early months. She admitted to feeling isolated, but used her yoga and cross-country running activities to get her through. She explained that the psychological and emotional feelings were almost more challenging than dealing with lectures, tutorials or trying to access support, plus she missed her family and friends in the Deaf community. It was the constant need to explain to people why she had not heard them or put up with their replies “Oh it doesn’t matter, it’s not important” if she queried what had been said – her disability was non-visible The process of disambiguation can be very tiring and as Ian Noon said in his blog
“Processing and constructing meaning out of half-heard words and sentences. Making guesses and figuring out context. And then thinking of something intelligent to say in response to an invariably random question. It’s like doing jigsaws, Suduku and Scrabble all at the same time.”
Amber joined the Student Union and found fellow activists who became friends as well as lobbyists for disability awareness and more inclusive teaching practices.
Those who could use sign language were rare, although help was available from interpreters during lectures and at other times, from note takers. Sometimes, Amber depended on fellow students’ notes, because it was hard to write, as well as concentrate on the lecturer or interpreter. Giving a lecturer her FM transmitter and microphone helped, especially when they turned away to write on a board or there were discussions and noise levels were raised. When lecture capture was in use, Amber always hoped the Automatic Speech Recognition (ASR) would provide good quality closed captions and subject specific words would be transcribed correctly. During the COVID-19 pandemic, Amber used text-based Q&As and comments when events happened in real-time with captions or subtitles and transcripts if available. Downloadable summaries and slide notes provided details missed on the video recording. Help and documentation about caption position adjustments, the text size and colour plus other settings for the conferencing system and access to a glossary of important subject related vocabulary has also been invaluable to aid comprehension.
Main Strategies to overcome Barriers to Access
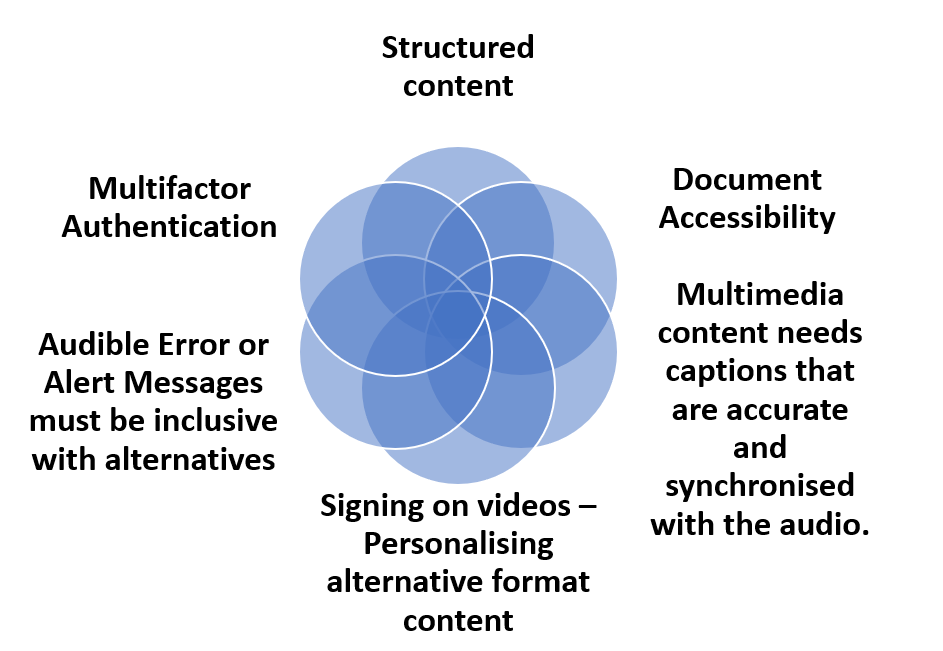
Multifactor authentication Amber has found that the best way for her to overcome the multifactor authentication issues is to use text messages (SMS) with a onetime password (OTP) plus a smart phone app. She has also found that finger biometrics on her phone helps with authentication or using an email system. She has a card reader for her bank but does not use speech recognition or voice calls for any verification, as she is never sure if she is going to get an accurate result or hear everything. (Web Content Accessibility Guidelines (WCAG) 2.2 Success Criterion 3.3.7 Accessible Authentication)
Multimedia content needs captions that are accurate and synchronised with the audio. Video and audio output complement so much of web content and Amber depends on good quality alternatives to make services both usable and accessible. It is not just the content, but also the way players work and the fact that any audio needs to be controlled and not start automatically. WCAG Guideline 1.2 – Time-based Media discusses content challenges and User Agent Accessibility Guidelines (UAAG) 2.0 provides technical details for developers such as Guideline 1.1 – Alternative content. The Authoring Tool Accessibility Guidelines (ATAG) also for developers and designers include the following guides related to those who have hearing impairments:
Signing on videos – Personalising alternative format content. Being able to adjust the position of the window with interpreter signing and/or captions may be important when content is filling the screen in different places as seen in the YouTube lecture on Beginning Robotics provided by University of Reading. Further guidance is available in their blog on Personalisation of viewing.
Structured content is important for everyone and helps Amber when she needs to pick out key topics. So clear headings and sub headings, use of white space and links to summaries, especially if they are related to video and transcript content, so she can see what is relevant to her needs. So regions, headings and lists all help to make a content more understandable.
Audible Error or Alert Messages must be inclusive. Notifications need to be available as very visible alerts as well as being audible and, on a phone or electronic watch, this can also be via vibration.
Document accessibility is important whether it is related to providing summaries and clear language or heading structure and bullet points, the aim is to make documents usable as well as accessible. WebAim have an easy to follow set of instructions for making ‘Accessible Documents: Word, PowerPoint, & Acrobat’.
Key points from Amber
“I am a very visual person and I like to see a detailed process as a diagram or image – step by step. I also really like having PowerPoint slides with all the main points…”
Interviews with Three Deaf Software Engineers in Bay Area (USA) Facebook video
TPGi provided a very helpful set of articles around an interview with Ruth MacMullen, who is an academic librarian and copyright specialist from York in the UK, called “Sounding out the web: accessibility for deaf and hard of hearing people” Part 1 and Part 2
The “PacerSpacer” – Simplicity in Controlling the Pace of Presentation Software (like PowerPoint) “One of the most important things you can do for Deaf/HH audience members when using presentation software such as PowerPoint is to allow sufficient time for them to read the slides before you begin talking. For Deaf/HH individuals, this means allowing time for them to stop watching the interpreter or you, switch their attention to a slide, and then return their attention to either the interpreter or you. With an interpreter, even more time is required since there is a lag time between what you say and the signing of that message.” DeafTec, Rochester Institute of Technology (USA)
The subject of automatic captioning continues to be debated but Gerald Ford Williams has produced a really helpful “guide to the visual language of closed captions and subtitles” on UX Collective as a “user-centric guide to the editorial conventions of an accessible caption or subtitle experience.” It has a series of tips with examples and several very useful links at the bottom of the page for those adding captions to videos. There is also a standard for the presentation of different types of captions across multimedia ISO/IEC 20071-23:2018(en).
However, in this article transcripts are something that also need further discussion, as they are often used as notes gathered from a presentation, as a result of lecture capture or an online conference with automatic captioning. They may be copied from the side of the presentation, downloaded after the event or presented to the user as a file in PDF/HTML or text format depending on the system used. Some automated outputs provide notification of speaker changes and timings, but there are no hints as to content accuracy prior to download.
The problem is that there also seem to be many different ways to measure the accuracy of automated captioning processes which in many cases become transcriptions. 3PlayMedia suggest that there is a standard, saying “The industry standard for closed caption accuracy is 99% accuracy rate. Accuracy measures punctuation, spelling, and grammar. A 99% accuracy rate means that there is a 1% chance of error or a leniency of 15 errors total per 1,500 words” when discussing caption quality.
The author of the 3PlayMedia article goes on to illustrate many other aspects of ‘quality’ that need to be addressed, but the lack of detailed standards for the range of quality checks means that comparisons between the various offerings are hard to achieve. Users are often left with several other types of errors besides punctuation, spelling and grammar. The Nlive project team have been looking into these challenges when considering transcriptions rather than captions and have begun to collect a set of additional issues likely to affect understanding. So far, the list includes:
Number of extra words added that were not spoken
Number of words changed affecting meaning – more than just grammar.
Number of words omitted
Contractions … e.g. he is – he’s, do not … don’t and I’d could have three different meanings I had, I would, or I should!
The question is whether these checks could be included automatically to support collaborative manual checks when correcting transcriptions?
Below is a sample of the text we are working on as a result of an interview to demonstrate the differences between three commonly used automatically generated captioning systems for videos.
Sample 1
Sample 2
Sample 3
So stuck. In my own research, and my own teaching. I’ve been looking at how we can do the poetry’s more effectively is one of the things so that’s more for structuring the trees, not so much technology, although technology is possible
so starting after my own research uh my own teaching i’ve been looking at how we can do laboratories more effectively is one of the things so that’s more for structuring laboratories not so much technology although technology is part of the laboratory
so stop. In my own research on my own teaching, I’ve been looking at how we can do the ball trees more effectively. Is one thing, so that’s more for structuring the voluntary is not so much technology, although technology is part little bar tree
Having looked at the sentences presented in transcript form, Professor Mike Wald pointed out that Rev.com (who provide automated and human transcription services) state that we should not “try to make captions verbatim, word-for-word versions of the video audio. Video transcriptions should be exact replications, but not captions.” The author of the article “YouTube Automatic Captions vs. Video Captioning Services” highlights several issues with automatic closed captioning and reasons humans offer better outcomes. Just in case you want to learn more about the difference between a transcript and closed cations 3PlayMedia wrote about the topic in August 2021 “Transcription vs. Captioning – What’s the Difference?”.
“When you watch videos that are not in your first language – if there are subtitles turn these into your chosen language to help explain the content.”
YouTube has closed captioning or subtitles on some videos and the video called “How to extract YouTube Subtitles (Interactive Transcript) in 2 minutes [HD]” illustrates some of the difficulties that occur with automatic captioning – A Frenchman speaking in English and when you view the subtitles by selecting the small list icon on the bottom right of the video player you will see that some of the words do not match what has been said but you can also translate the words into your chosen language. The results will be variable! In this video you will see how you can take the transcript and improve the results.