We have created 6 computer science student personas who need to use different ways of accessing online materials and elearning systems to highlight some of the issues encountered. In some ways these personas aim to fit into the NNgroup definition in their article on Personas vs. Jobs-to-Be-Done. Page Laubheimer in 2017 said “Jobs-to-be-done focus on user problems and needs, while well-executed personas include the same information and also add behavioral and attitudinal details.”
We hope our personas are ‘well executed’ and the features mentioned relating to accessibility and usability will help support individual preferences when using the web. However, there may be overlaps and there will be techniques and criteria that you may feel are missing. So it is important to think ofthe content as just being a flavour of what can be offered when creating inclusive content, design and development. Follow the links for more information about individual criteria. Content will also go out of date and need checking, so do contact us if you spot any issues.
Each Persona has a video relevant to particular issues that might be encountered when web services fail to be accessible and cause barriers. Matt Deeprose and the team from the University of Southampton have provided a wonderful explanation about several aspects of web development in a video ‘The impact that high quality mark-up can have on accessibility, performance, and discoverability‘. Matt’s Github example web page of how he has used the code he discusses, also has the video transcript and links to many other resources. A good way to start on the accessibility, usability and inclusion journey.
This blog is about the interesting idea that when you have biases that affect the accuracy results of a transcription made with automatic speech recognition (ASR) you might consider using voice cloning to gather different speech types that could improve the large language model that is used for the speech to text output. Voice cloning uses artificial intelligence (AI) with the aim of creating a similar voice to one provided by a speaker emulating articulation and intonation patterns. It is not the same as speech synthesis where a user can choose from a limited number of voices to provide text to speech. In theory once you have cloned your voice, it is possible to fine-tune it to work with any language as well as altering pitch and pace for different emotions. I might sound a bit robotic at times and lacking in emotion when you expect some excited sounding exclamations but at other times it can be alarmingly accurate!
However, as we have discussed in a past blog about evaluating ASR output, when it comes to transcriptions, errors may occur due to the way a person enunciates their words and the quality of the voice. If English is the language being used various accents, dialects, aging voices both male and female, lack of clarity and speed of speaking can result in an increase in Word Error Rates. Pronunciation may also be affected by imperfect knowledge about how words are said, whether that is due to their complexity or the speaker is working in English that is not their first language.
Could AI help with a series of voices that have been cloned from the very types of speech that cause problems for automated transcriptions? We have been experimenting and there are several issues to consider. The first issue arises when you discover the company selling the cloned voices is situated in the United States and when you try your British English with limited training of the model your voice develops an American accent or in the case of another company a uniquely European type of accent that has a hint of German because the company is based in Berlin. These voices can be tweaked and would probably improve if several hours of training occurred.
This leads to the second issue that is the amount of dictating that has to occur to improve results. – Tests with 30 minutes improved the quality but that did not solve some problems especially when working with STEM subjects where complex words may have been incorrectly pronounced during the training or did not match that expected in previously undertaken training by the voice cloning company. So unless a word has been pronounced with an American accent the system tends to produce an error or changes the original pronunciation to one accepted in the United States but not the United Kingdom!
Finally, there is always a cost involved when training is needed for longer periods and as a lecture is usually around 45 minutes long it is important for any experimentation to capture a speaker for at least this period in order to cater for the changes that can occur in speech over time. For example, tiredness or even poor use of recording devices can occur changing the quality of output. It has also been found that the cloned voice may not be perfectly replicated if you only have short training periods of a few minutes. But, 100 sentences of general dictation, where all the words can be accurately read, can produce a good result with clear speech for a transcription. In the case of a basic account with Resemble.ai transcripts have to be divided into 3000 character sections which means you need on average at least 11 sections of cloned voice for a whole lecture. Misspoken words can be changed and using the phonetic alphabet allows for adaptations to particular parts of words, emotion can be added but it would take time and there are several language options for different accents.
With all the discussions around ChatGPT and Automatic Speech Recognition (ASR) it would seem that Large Language Models (LLMs) as part of a collection of Artificial Intelligence (AI) models could provide us with language understanding capability. Some models appear to be able to answer complex questions based on the amazing amounts of data or information collected from us all. We can speak or type a question into Skype and Bing using ChatGPT and the system will provide us with an uncannily appropriate answer. If we want to speed read through an article the process of finding key words that are meant to represent a main point can also be automated as can a summarisation of content as described in the ‘ChatGPT for teachers: summarize a YouTube transcript’
But can automated processes pick out the words that might help us to remember important points in a transcript, as they are designed to do when manually chosen[1]?
We rarely know where the ASR data comes from and in the case of transcribed academic lectures, the models used tend to be made up of large generic datasets, rather than customised educational based data collections. So, what if the original information the model is gathering is incorrect and the transcript has errors or what if we do not really know what we are looking for when it comes to the main points or we develop our own set of criteria and the automatic key word process cannot support these ideas.
Perhaps it is safe to say that keywords tend to be important elements within paragraphs of text or conversations that could give us clues as to the main theme of an article. In an automatic process they may be missed where there is a two-word synonym such as a ‘bride-to-be’ or ‘future wife’ rather than ‘fiancée’ or a paraphrase or summary that can change the meaning:
Paraphrase: A giraffe can eat up to 75 pounds of Acacia leaves and hay every day.[2]
Original: Giraffes like Acacia leaves and hay and they can consume 75 pounds of food a day.
Keywords are usually names, locations, facts and figures and these can be pronounced in many different ways when spoken by a variety of English speakers[3]. If the system is using a process of randomly learning from its own large language model there maybe few variations in the accents and dialects and perhaps no account of aging voices or cultural settings. These biases have the potential to add yet more errors, which in turn affect the relevance of chosen key words generated through probability models.
Teasing out how to improve the output from AI generated key words is not easy due to the many variables involved. We have already looked at a series of practical metrics in our previous blog and now we have delved into some of the other technological and human aspects that perhaps could help us to understand why automatic key wording is a challenge. A text version of the mind map below is available.
Figure 1. Mind map of key word issues including human aspects, when working with ASR transcripts. Text version available
In the previous blog we discussed some of the metrics that we felt needed to rbe explored in order to carry out a fuller evaluation of ASR recordings in order to try to address some of the issues occurring in the output to captions and transcriptions.
Recently we have developed a range of practical metrics evaluated by a series of scores and value-added comments. This was felt necessary to solve the issue of selection bias in ASR that seems to highlight errors due to pronunciation differences affected by age, gender, disability, accents and English as a foreign language when listening to lecturers across a range of subjects. It is hoped these can be addressed by providers using differently biased input data that is customized, instead of using one single accuracy percentage to denote the performance of the ASR services. Evaluators also need to be aware of these issues and suggest the need for more inclusive training data to enable corrections to automatically occur in a proactive manner.
In the table below the list of items that may be used in a review has been expanded well beyond those usually used to find the type of word errors, omissions or additions that are occurring.
SpeakerSpeech
EnvironmentNoise
Content – What is expressed
Technology Hardware
Recording
Pronunciation Clarity Speed Loudness Pitch Intonation Inflection Accent, Age, Gender, Use of Technology Too far away / near the microphone
Ambient noise/continuous Reverberation Sudden noise Online/Offline User device Room system Conversation vs Presentation Single speaker Overlapping speakers Multi-speakers
Complexity Unusual names, locations, and other proper nouns Technical or industry-specific terms Out of Vocabulary / not in the dictionary Homonyms
Smart phone Tablet Laptop Desktop Microphone Array Headset Built-in Hand held Camera Specialist /Smart Computer Mobile
Direct audio recording Synthetic speech recording Noise-network distorted speech Connectivity Live / Real-Time Recorded
Table 1. Additional practical metrics to support the evaluation of ASR outcomes
When it comes to pronunciation or typical morphosyntactic differences in the way a language is used, developers may be able to pre-empt and automate corrections for consistent errors. An example includes articulation errors that are typical for those speaking English as a foreign language such as the omission of “th”, “v” and “rl” sounds that do not appear in some Chinese dialects.
Age and gender biases could also be improved using semi-automated annotation systems, but speaker style remains an issue that is hard to change when there is direct ‘human-machine interaction’ rather than someone reading text.
Moreover, there still remains the manual process of checking for metrics, such as those that examine the way technology is used. This type of problem can be judged visually if the camera catches the interactions and in an auditory manner, such as walking away from the microphone or turning ones back to the camera etc. AI Video content analysis is moving apace and these techniques could help us in time!
Ultimately the training data is the main issue but automated bias mitigation techniques are being explored by researchers and the outcomes look promising and there also needs to be some swift designing of a more sophisticated and adaptable ASR performance metric evaluator to automate the process of reviewing output!
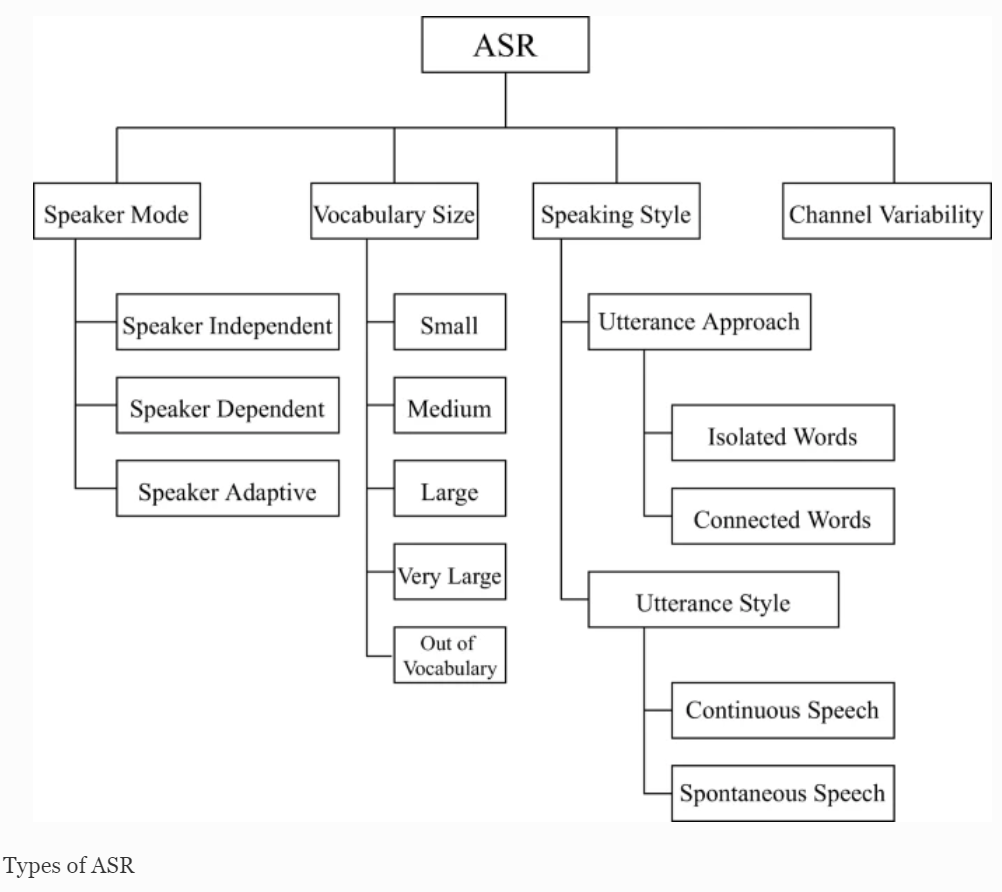
This is just the start of a user needs analysis related to the way we think about Automatic Speech Recognition (ASR) challenges and our requirements for captions and transcripts to help those watching and listening to streaming videos and audio.
Working from left to right in the above diagram the authors of this paper ask us to think about a ‘Speaker Mode’ such as a trained speech pattern from a sole user who, with a good speaking style, can result in good ASR results. This mode is compared to an untrained speech pattern from one person or multiple speakers with overlapping conversations which can be harder for ASR models. Moving across to the ‘Vocabulary Size’ used in the conversations or presentations, there may be large and complex sections of text which, when considered alongside different ‘Speaking Styles’, can also affect output. ‘Channel Variability’, such as a noisy environment is a further challenge. The technologies used (microphones and cameras) may also be unsuitable for the best results. Finally, latency when live streaming ASR involves the time it takes for data to get to the ASR servers and back again. This process also includes how long the transcribing takes. Both types of latency has an impact on the accuracy of captions and transcriptions.
file format acronyms and others
However, having accepted all these challenges and several other issues that may have been missed, there is the essential task of thinking about user needs. In our case this involves student needs and the desire for increased flexibility in the way learning occurs at a higher education level. There remains the wish to have 100% accurate captions that fit the timeline of a conversation or presentation / lecture, but some users may wish to have different size fonts or colours as the text crosses the screen, others may wish to have key words highlighted. Then there are the transcripts that can offer easier reading by omitting many of the natural non-word insertions such as ‘ums’ and ‘uhs’, but need to accurately capture multiple acronyms to help understanding, so they can be defined at a later date.
As we explore the way applications present captions and transcripts, it is not surprising that there seem to very few discussions about personalisation and customisation of captions and transcripts for educational use. Most students are provided with instructions for the various systems, with little choice as to whether they wish to have slides on show or hidden, titles in larger text and paragraphs with timings. Then it may be important for all the inserted non-words to be left in place because they can add to the emotional content of a presentation. Some captions are offered as a stream of text as a type of transcript. This is how they are provided by YouTube, including all the timings down to two seconds apart, with phrases in long columns. The content can be copied and pasted into a document, but it is not that easy to read for note taking, with very minimal punctuation and liberal capturing of non-word insertions.
Other systems such as Otter.ai offer a downloadable transcript that has speaker recognition and key points as an outline targeted for use in meetings. These options could be handy for lecture notes. The system strips out any non-word insertions, adds punctuation and copes well with many complex words and different speakers, giving each one a number.
As a way of personalising video viewing and lecture capture, it is possible to combine the YouTube experience with captions by then converting the MP4 video file (if it is downloadable) into an MP3 format (free VLC offers this option) or use a web service and then upload it to Otter.ai as a free trial! It really does not take long and the process allows me to analyse Word Error Rates for testing accuracy, by comparing documents as well as using highlighting and adding annotations!
Warning: Obviously because the process described involves AI and automation, not every aspect of the captions or transcript output can be guaranteed to be 100% correct, so there is still the need to have manual checks in place if a verbatim output is required.
As everyone seems to be adding a touch of AI to everything, we thought we would wish you all a wonderful festive season and take a break, leaving the task of generating images and answering questions to the automated systems!
Did you know you can ask ChatGPT anything and it will have an answer? What more could you want as you leave for a few days off! Autogenerated FAQ pages to help those who want to learn more about specialist subjects.
OpenAi can also be helpful if you are late getting those cards out. Why not make a unique card by just typing a description of your requirements… “A Christmas card with dogs” – you can always ask for variations on the theme!
Finally, have fun and see if you can beat the AI models at generating emojis from film titles whilst helping to improve OpenAI research! Happy Christmas and New Year ?✨?
YouTube video in German with automatic speech recognition captions translated into English https://youtu.be/2c9qaNqSOS0
Around this time last year (November 2021) we discussed the challenges that are linked to the evaluation of captions generated by the use of Automatic Speech Recognition (ASR) in two blogs ‘Collaboration and Captioning’ and ‘Transcripts from Captions?’
We mentioned other methods in comparison to word error rates where any mistakes in the caption are caught and provided as a percentage. This does not take into account how much is actually understandable or whether the output would make sense if it was translated or even used in a transcript.
“Word Error Rate (WER) is a common metric for measuring speech-to-text accuracy of automatic speech recognition (ASR) systems. Microsoft claims to have a word error rate of 5.1%. Google boasts a WER of 4.9%. For comparison, human transcriptionists average a word error rate of 4%. “
Helena Chen in her blog goes on to explain how to calculate WER
“Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
Where errors are:
Substitution: when a word is replaced (for example, “shipping” is transcribed as “sipping”)
Insertion: when a word is added that wasn’t said (for example, “hostess” is transcribed as “host is”)
Deletion: when a word is omitted from the transcript (for example, “get it done” is transcribed as “get done”)”
She describes how acoustics and background noises affect the results, although we may be able to cope with a certain amount of distraction and understand what is being said. She highlights issues with homophones and accents that may fail with ASR, as well as cross talk where ASR can omit one speaker’s comments, that could affect the results. Finally, there is the complexity of the content and as we know with STEM subjects and medicine this may mean specialist glossaries are needed.
Improvements have been made by the use of natural language understanding with the use of Artificial Intelligence (AI). However, it seems that as well as the acoustic checks, we need to delve into the criteria needed for improved comprehension and this may be to do with the consistency of errors that can be omitted in some situations. For an example a transcript of a science lecture may not need all the lecturer’s ‘ums’ and ‘aahs’, unless there is the need to add an emotional feel to the output. These would be counted as word errors, but actually do not necessarily help understanding.
There may also be the need to flag up the amount of effort needed to understand the captions. This involves the need to check output for automatic translations, as well as general language support.